SingleStore:Cloud-Native Transactions and Analytics in SingleStore论文阅读
传统OLTP 系统主要用于处理大量的交易性操作,例如在银行系统中处理用户的交易、在电子商务平台中处理订单、在企业管理系统中处理日常业务操作等。其主要特点是:
- 对事务的并发处理能力要求高(吞吐量、TPS、latency)。
- 数据的一致性要求较高(严格的事务语义)。
因此,OLTP 系统通常设计为面向事务的、高并发的、强调实时处理和数据一致性的系统。
而分布式 OLAP 系统主要用于进行复杂的多维数据分析和查询,例如在数据仓库中进行销售分析、市场趋势分析、业务预测等。这些操作通常需要对大规模数据进行聚合、分组和计算,并且通常是针对历史数据进行分析。其主要特点是:
- 需要对海量数据进行批量处理(TB、PB级的数据)。
- 不需要严格的事务语义,通常是由OLTP数据库通过ETL转换过来的,在ETL的过程中不需要完整的支持事务。
存储结构
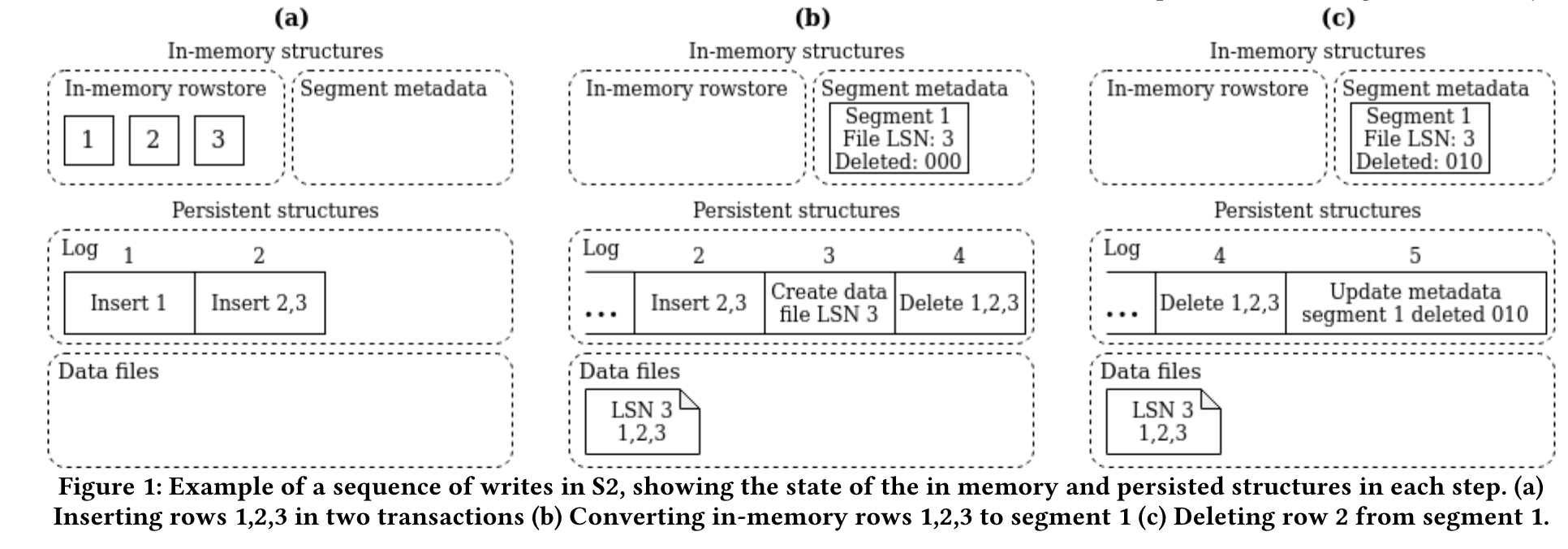
- In-Memory的LSM-Tree(当然还有其对应的WAL日志),用来存小量TP修改的数据
- 磁盘上存储的以段(Segment)为单位的持久化数据,列存
从存储侧来看,和大多数的以列存基线数据+内存增量数据为模式的数据库相同,如列存模式的OceanBase、SAP Hana.
不同点是S2DB是云原生的,底层接了一层云存储,在计算节点也有自己的本地存储,事务提交后先在本地存储持久化,然后异步地移动到blob store里面,这么做是为了减少事务提交时的等待。本地存储使用的是SSD,只存储一些热点的数据,比如日志尾页。但这么做其实缺点也很明显,就是额外增加了一层数据传输,并且本地存储没有弹性扩容的功能。
一些优化点:
- 传统LSM-tree删除的时候需要标记删除,在single store里面实际上是去修改meta 文件里面的delete bitmap
- 行级别的锁,原理是在删除或者更新过程中起一个自治事务,把列数据移动到行存,然后置bitmap
以join为例,有local join, broadcast join, shuffle join, semi join等等。