查询优化
Heuristics/Rules 规则/静态触发
当查询中的某些部分满足我们的规则或者条件,我们就重写这部分.这部分需要我们去检查catelog.
Cost-based Search
方法的思想是使用一个模型去评估一个查询的负载,然后使用多种不同的查询计划去替换这个查询,找出最小负载的方案。
下面是整个查询优化过程
Relational Algebra Equivalences(等价关系代数)
- predicate pushdown:在join前尽量过滤数据。
- 对过滤条件进行排序,让更具有分辨性的条件排在前面。
- 对复杂判断进行简化
- 对于行存储类型数据库,projection越早越好。
Plan Cost Estimation
- CPU
- 磁盘
- 内存
- 网络
在数据库的catelog中,会维护相关信息,并且在特定时间或者遍历表的时候更跟这些信息,在执行查询之前,将这些变量带入公式,计算出最小代价的查询。在系统中,我们定义一些统计量:
- $N_R$: 关系R的tuple数量
- V(A,R):属性A不同值的数量
- Selection Cardinality:$N_R$/V(A,R)
- selectivity: 选择率,给定一个条件,计算table中符合条件的tuple数量
- Range Predicate:计算范围值的比例,有点像概率计算,因此可以引入概率论中的结论,但是为了计算方便,有下面三个前提:

直方图法
对于数据分布不均匀的关系,在一些高端数据库中会使用直方图来跟踪数据的分布。对于数据量极大或者属性值分布很广的情况,我们会使用相同宽度的bucket来记录值的分布,但是这种情况会导致某个桶内数据分布极不均匀的情况,我们可以使用分位数来解决这个问题,即累计一定比例的数据分桶,桶的宽度可变,但是总体占比大致相当。
采样法
对于直方图,其实是对表中数据的一种缩略表达,那么在大数据量的table中,我们可以直接采样来近似代表整个表的数据分布。当表进行大规模更新或者到达一个指定时间点,我们去更新这个采样表。
Plan Enumeration
单关系查询计划
- 循序遍历
- 二分查找(对于聚集索引)
- 索引遍历
多关系查询计划
left-deep join tree
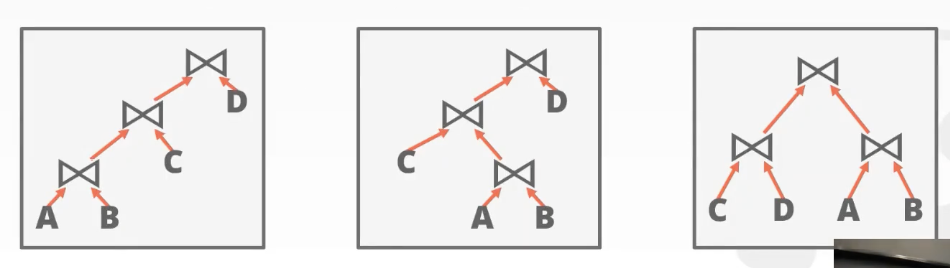
在上面三个查询树中,System R不考虑后面两个,只考虑第一种。为什么采用第一种?后面两种实现过程中会有大量结果溢出到磁盘,影响性能。步骤(System R based)

步骤(遗传算法)

Nested Sub-queries
通常情况下将where作为函数,穿入参数然后返回一组值,有两种方法进行查询优化:
- 重写查询,去除关联性,让其扁平化
- 将内部查询提取出来作为单独查询来执行,将结果缓存起来,这样不用每次执行上层查询都再执行一次子查询