关键点
- 数据库中的table不能完全放到内存中
- 计算得到的中间结果不能完全放入内存中
排序算法
- 外部排序(多路归并排序)
- 读取B个page到内存,对page排序并且回写到磁盘
- 使用prefetch预读加速
- B+树
- 如果需要排序的key作为b+树存储,可以复用b+树
- 只能在聚簇索引(物理相邻)的b+树上使用,因为如果不是聚簇索引,每次获得数据都需要一次磁盘io
聚合
- 排序聚合
- 非排序聚合
- external hashing aggregate

- external hashing aggregate
Join操作
data在查询语法树中的传递
- 一个常规做法是将两个表所有属性拷贝到新表中,这样下面的操作不必再考虑前面的数据,也就是不用再到磁盘中进行retrieve.
- 另一种方法是指穿入我们所需的最小限度信息(join keys).然后根据这些信息在后面的操作总从数据库中获取tuple的其他数据.这种方法叫做late materialization,对于列式存储比较友好,因为不用将其他列的信息粘合起来,这些信息通常位于不同的page中。现在这种优化很少,因为数据的获取(第一阶段)的代价通常很大。
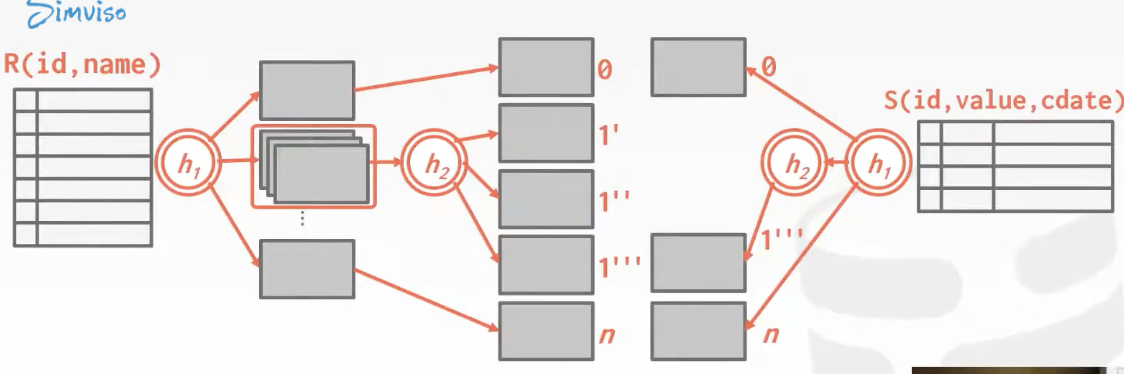
Nested Loop Join


这是一种非常暴力的方法,一种优化手段是block nested loop join,这种方法把outter table的tuple缓存,减少了对inner table的io次数。


另一种优化手段是index nested loop join,在内循环中去查询索引,这样避免了遍历操作,是O(logn)的复杂度,但是如果要查询的索引不是聚簇索引,还需要一次回表操作。
Sort-Merge Join
首先是对需要join的key(s)进行排序,然后利用两个游标在两个有序表上进行匹配。

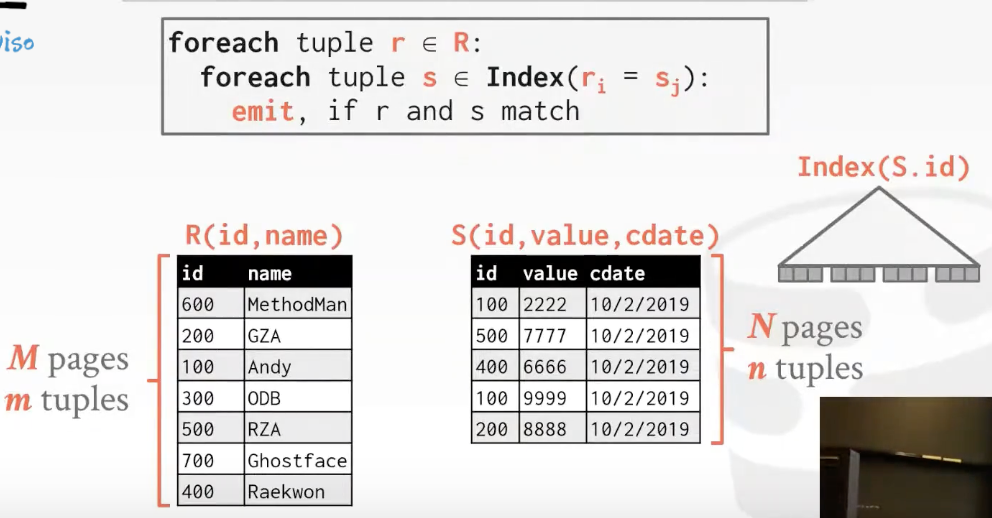
Hash Join
原理就是对两个表中需要join的那个值进行hash操作,那么相同的值肯定会映射到一个partition中,我们每次只需要在一个partition中进行比较就行了。

在分布式场景下,可能两个表存在不同的主机上,那么传递哈希表是一个非常消耗资源的事,一个优化手段是使用布隆过滤器,布隆过滤器通常只有几kb大小,非常容易在主机之间进行网络通信,在建立第一个表的哈希表的时候填充布隆过滤器,那么我们对第二个表进行哈希的时候,可以直接判断是否存在。
哈希之后的数据量可能非常大,不能放在内存中,因此我们可以使用Grace Hash Join优化。
也就是分别对两个表进行哈希,然后对每对bucket进行Nested Loop Join,如果bucket也不能完全放到内存中,那就再进行一次哈希,递归进行。
总结

处理模型(processing model)
迭代模型(Iterator Model)

每一个查询操作符都实现一个Next函数,函数调用其子节点的Next函数。Next每次处理一个tuple数据,需要迭代所有tuple才能完成所有操作。
一些操作符必须获得所有子节点的tuple,例如Joins,Subqueries,Order ByMaterialization Model
不同于迭代模型,每次子节点都将整个结果传递给上层

在OLTP中进行点查询,这种方式比较高效,但是在OLAP中存在大量的中间结果,会产生锁延时,并且对于含有LIMIT的查询,如果数据量很大,每次传递给上层所有数据,这种资源消耗是不必要的。Vectorization Model
对迭代模型的优化,每次不是产生一个tuple,而是产生一个batch的tuple.
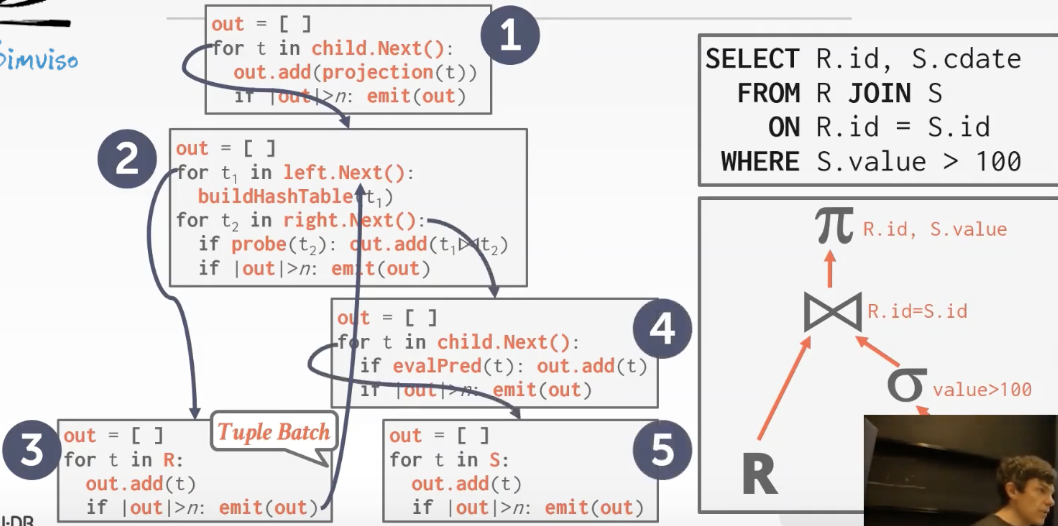
这种方式能够使用SIMD技术对数据进行分析计算,对于OLAP非常友好
Access Method
- Sequential Scan
普通遍历,对每页的tuple基于cursor做遍历,这通常效率非常低,有一些优化:预读,Buffer Pool Bypass,并行化,Zone Maps,Late Materialization,Heap CLustering- Zone Maps:预先对page中的数据做聚合计算,DBMS在访问page的时候先去检查这些字段,如果不需要访问就直接跳过这个page

- Late Materialization:在列式存储数据库中,由于数据被按列存储到不同的page中,那么在每次opertaor之后,不用将整个tuple传给上层,直接传tuple对应的offset值,然后到root节点再到不同page中获取每一列的值。
- Zone Maps:预先对page中的数据做聚合计算,DBMS在访问page的时候先去检查这些字段,如果不需要访问就直接跳过这个page
- Index Scan
- Multi-Index Scan:通过不同的索引进行多次查找,基于我们的判断在对结果进行合并
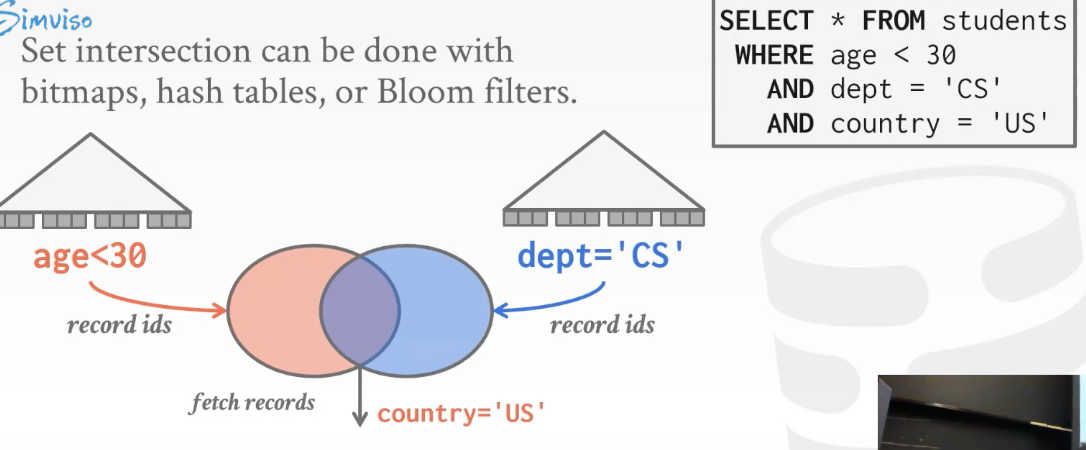
- 非聚簇索引的随机IO问题:对于非聚簇索引,我们可以不去一一随机IO,我们先将要访问的page id记录下来排序然后去一次访问page,拿到所有需要的tuple.
- Multi-Index Scan:通过不同的索引进行多次查找,基于我们的判断在对结果进行合并
表达式评估(Expression Evaluation)
DBMS将WHERE语句转化成一个expression tree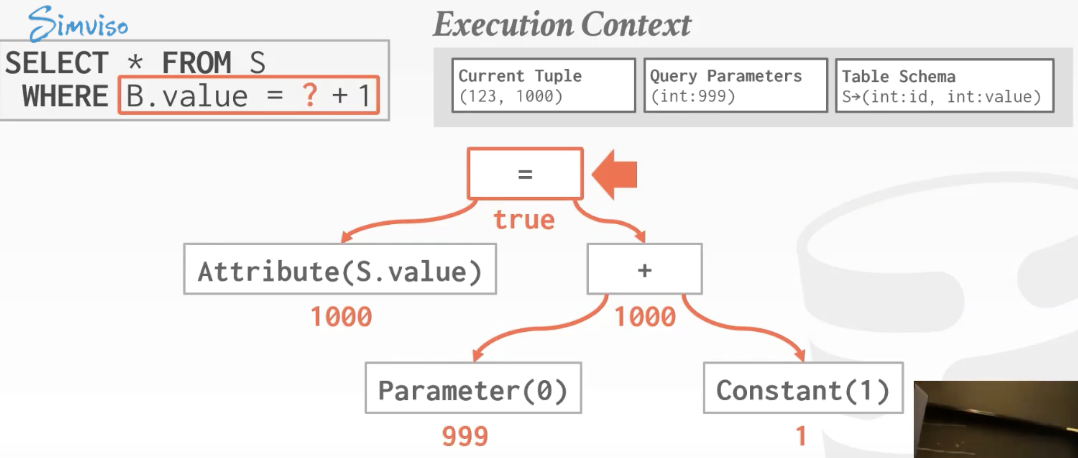
每次遇到一个tuple,去匹配这个树,这样的话效率很低。