B+树索引
- 聚集索引
- 非聚集索引(辅助索引)
- Cardinality
- 获取B+树叶子节点的数据,记为A
随机获得B+树索引中8个叶子节点。统计每个页不同记录的个数,分别记为P1,P2…P8
计算cardinality = (P1+P2+…P8)A/8
- 获取B+树叶子节点的数据,记为A
OLAP 和 OLTP
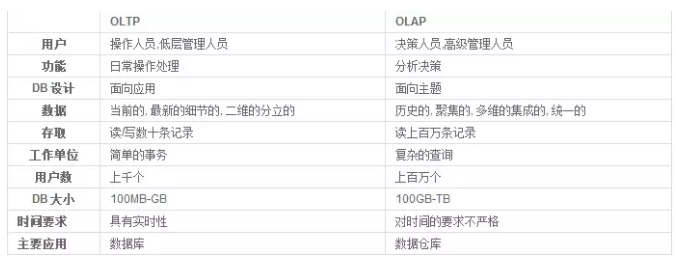
OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。
OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。OLAP,也叫联机分析处理(Online Analytical Processing)系统,有的时候也叫DSS决策支持系统,就是我们说的数据仓库。
在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
联合索引
对表上多个列进行索引。
覆盖索引
就是能从辅助索引中得到所有查询信息的记录。
Multi-Range Read优化
当表的数据非常多以至于无法放入缓存时,基于二级索引的范围扫描读取数据会造成较多的硬盘随机读。如果启用了MRR优化,MySQL首先会基于索引进行数据定位并收集满足条件的keys,然后再对这些keys进行排序,这样可以以主键的顺序进行表行的读取,能够减少随机读的数量。MRR优化的目的就是通过对keys排序后的一定程度的顺序读减少随机读的数量。
ICP优化
在不启用 ICP 的情况下利用二级索引查找数据的过程:
- 用二级索引查找数据的主键;
- 用主键回表读取完整的行记录;
- 利用 where 语句的条件对行记录进行过滤。
启用 ICP 的情况下利用二级索引查找数据的过程为:
- 用二级索引查找数据的主键;
- 如果二级索引记录的元组里的列出现在 where 条件里,那么对元组进行过滤;
- 对索引元组的主键回表读取完整的行记录;
- 利用 where 语句的剩余条件对行记录进行过滤;
倒排索引
使用full inverted index实现,表现形式为{单词,(单词所在文档的ID,在具体文档中的位置)}