RDB
- 文件结构

一个完整的RDB文件包含上面各部分。
REDIS:5字节,检查是否为RDB文件。
db_version:4字节,字符串表示的整数,记录版本号。
database:0或n个数据库的键值对数据。
EOF:1字节,表示正文结束。
check_sum:8字节长无符号整数,保存一个校验和,根据前面四个部分计算得到。
如下是一个有两个数据库的RDB文件。

每个数据库里面包含下面几个部分:
SELECTDB:1字节,表示接下来是一个数据库号码;
db_number:数据库号码,1/2/5字节,当读入时,服务器根据select切换;
key_value_pairs:保存数据库中所有键值对数据。
- key_value_pairs
下图展示了一个不带过期时间的键值对: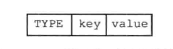
TYPE:1字节类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14/* Dup object types to RDB object types. Only reason is readability (are we
* dealing with RDB types or with in-memory object types?). */
/* Object types for encoded objects. */带有过期时间的键值对:
EXPIRETIME_MS:1字节,表示接下来是一个时间。
ms:8字节带符号整数,过期时间,一个毫秒单位UNIX时间戳。
- value的编码
字符串对象:
存在压缩版
无压缩版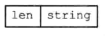
列表对象

集合对象

哈希表对象

有序集合对象

压缩列表
保存这种文件的方法是:(1)将压缩列表转换成一个字符串对象(2)将字符串对象保存到RDB文件。
AOF
简单来说AOF就是讲命令按顺序写入文件来持久化。
总的来说分为三个步骤:命令追加,文件写入,文件同步。
命令追加
在redisServer结构体重有一个aof_buf缓冲区:1
2
3struct redisServer{
sds aof_buf;
};AOF文件中是以命令请求协议格式保存的,因此命令追加是如下形式:
1
2
3redis>SET KEY VALUE
*3\r\n$3\r\nSET\r\nKEY\r\n$5\r\nVALUE\r\n文件写入
在服务器进程每次时间循环结束之前,可以考虑将aof缓冲区的数据写入文件。写入策略有:(1)always:将缓冲区所有内容写入并同步到AOF文件(2)everysec:将缓冲区所有内存写入AOF,如果上次同步AOF文件的时间超过1s,那么再次对AOF同步,并且由一个线程专门负责执行(3)写入AOF但不同步。
所谓同步,就是讲aof_buf拷贝到内核缓冲区,写入就是讲内核缓冲区的数据写入磁盘。这三种方式第一种最耗时但是最安全,第二种保证出现故障最多丢失1s的数据,最后一种方式写入最快但是不安全。载入和数据还原
因为本身存的是命令,只需要再执行一遍命令就可以了,在读取AOF文件之后,redis创建一个伪客户端发出命令。AOF重写
由于AOF文件记录所有命令,因此文件体积会迅速膨胀,因此redis提供对AOF文件重写功能。
核心思想就是,直接从数据库读取键值对,生成一条命令,来替代所记录的所有相关命令。
例如: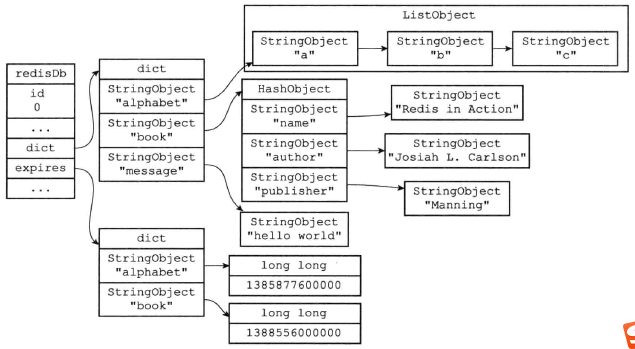
可以用下面命令代替:1
2
3
4
5
6SELECT 0
RPUSH alphabet "a" "b" "c"
EXPIREAT alphabet 1385877600000
HMSET book "name" "Redisin Action" "author" "Josiah L. Carison" "publisher" "Manning"
EXPIREAT book 1388556000000
SET message "hello world"
如果直接使用主线程来重写,势必会造成主线程长时间繁忙,无法处理用户请求,因此在实际实现中使用子进程来写。
使用子进程写的过程中,如果父进程对数据库进行修改,就回造成数据不一致问题,针对这个问题,redis设置了AOF重写缓冲区。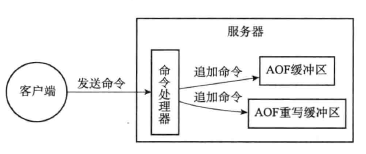
在子进程执行重写的过程中,需要执行下面三个工作:
1)执行客户端的命令
2)将执行后的命令追加到AOF缓冲区
3)执行后的写命令追加到AOF重写缓冲区
当子进程完成AOF重写,给父进程发一个信号,父进程接受信号之后,调用信号处理函数:
1)将AOF重写缓冲区所有内容写入新AOF,这时新AOF文件与当前数据库数据一致。
2)对新的AOF改名,原子性覆盖现有AOF文件。