3.0哈希表
下面是哈希表结构:
1 | /* This is our hash table structure. Every dictionary has two of this as we |
- table是一个数组
- size记录哈希表的大小,也就是table数组的大小
- used记录了哈希表目前已有节点的数量
- sizemask = size - 1
形式如下图所示: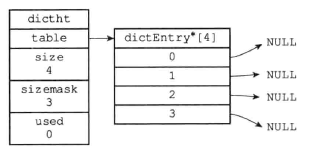
哈希表节点:
1 | typedef struct dictEntry { |
- key保存键
- v保存键值对的值,可以是指针,或者uint64_t整数或者一个int64_t整数。
- next指向另一个哈希表节点的指针,由此可以看出,redis使用链表法来解决冲突
下图展示了一个冲突的哈希表: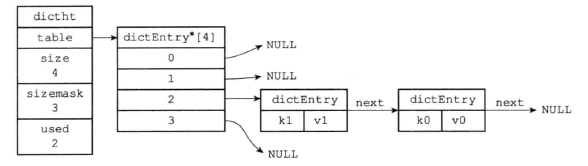
3.0字典
- 基本数据结构
数据结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
typedef struct dictType {
// 哈希函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
//销毁键
void (*keyDestructor)(void *privdata, void *key);
// 销毁值
void (*valDestructor)(void *privdata, void *obj);
} dictType;
- type属性和privdata是针对不同类型的键值对,为创建多态字典设置的
- dictType是一族绑定特定类型键值对的函数族,privdata是这些函数的可选参数
- ht是两个哈希表,ht[1]只会在ht[0]rehash的时候使用
- rehashidx 记录rehash进度,如果没有rehash就为-1
下面是一个正常状态下的字典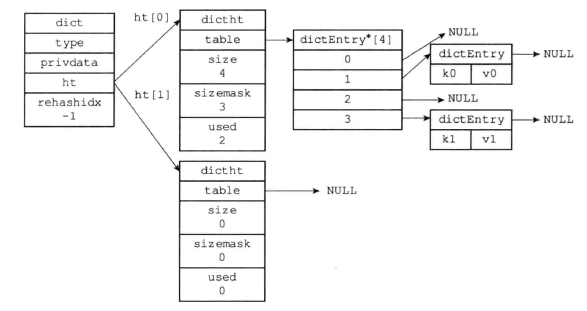
- 插入哈希表
1 | hash = dict -> type -> hashFunction(key); |
- 首先使用定义的哈希函数计算键的哈希值
- 然后使用与操作将hash掩码到长度范围内
- 解决键冲突
使用链表法解决冲突,一个优化是将新添加的键值对插入到链表的头部。
- rehash
- 为字典的ht[1]哈希表分配空间
- 如果是扩展操作,那么sizeof ht[1] = min(n),2^n >= ht[0].used * 2;
- 如果是收缩操作,sizeof ht[1] = min(n), 2^n >= ht[0].used
- 将保存在ht[0]的所有键值对重哈希到ht[1]
- 释放ht[0],ht[0] = ht[1], h1 = empty.
- 哈希表的收缩扩张条件(满足下列条件之一即可)
负载因子:1
load_factor = ht[0].used / ht[0].size;
- 服务器没有在执行BGSAVE或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1
- 服务器目前正在执行这两个命令,并且哈希表的负载因子大于等于5.
- 渐进式rehash
- 为ht[1]分配空间
- 维护rehashidx,并设置为0
- 在rehash期间,对字典添加删除,查找或者更新,都在ht[1]中进行,还需要将当前rehashidx对应的ht[0]的所有键值对rehash到ht[1],然后rehashidx + 1
- 当所有键值对完成哈希后,rehashidx设置为-1
5.0版本
- hash函数
- 服务端的hash函数使用的是siphash算法
- 客户端使用的是times_33函数
- 基本结构和3.0无太大变化,增加了iterators字段
1
2
3
4
5
6
7typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict; - 迭代器遍历
iterators字段,用来记录当前运行的安全迭代器数,当有安全迭代器绑定到该字典时,会暂停rehash操作。Redis很多场景下都会用到迭代器,例如:行keys命令会创建一个安全迭代器,此时iterators会加1,命令执行完毕则减1,而执行sort命令时会创建普通迭代器,该字段不会改变.
字典迭代器主要用于迭代字典这个数据结构中的数据,既然是迭代字典中的数据,必然会出现一个问题,迭代过程中,如果发生了数据增删,则可能导致字典触发rehash操作,或迭代开始时字典正在进行rehash操作,从而导致一条数据可能多次遍历到。那Redis如何解决这个问题呢?
普通迭代器通过指纹字段,每次迭代就会检查字典是否改变,如果改变(增删改查rehash)直接退出。安全迭代器通过设置标志位,设置完之后,rehash函数检查标志位后不会进行rehash,但是可以进行增删改查操作。
数据结构如下:
1 | /* If safe is set to 1 this is a safe iterator, that means, you can call |
- d:迭代的字典
- index:当前迭代的索引值
- table,safe:table为正在迭代的Hash表,即ht[0]与ht[1],safe用于表示当前创建的是否为安全迭代器
- entry,nextentry:当前和下一个节点
- fingerprint:字典的指纹,随字典改变而变
简单介绍完迭代器的基本结构、字段含义及API,我们来看下Redis如何解决增删数据的同时不出现读取数据重复的问题。Redis为单进程单线程模式,不存在两个命令同时执行的情况,因此只有当执行的命令在遍历的同时删除了数据,才会触发前面的问题。我们把迭代器遍历数据分为两类:
- 普通迭代器,只遍历数据:
普通迭代器迭代字典中数据时,会对迭代器中fingerprint字段的值作严格的校验,来保证迭代过程中字典结构不发生任何变化,确保读取出的数据不出现重复。主要步骤如下:
- 调用dictGetIterator函数初始化一个普通迭代器,此时会把iter->safe值置为0,表示初始化的迭代器为普通迭代器;
- 循环调用dictNext函数依次遍历字典中Hash表的节点,首次遍历时会通过
dictFingerprint函数拿到当前字典的指纹值; - 当调用dictNext函数遍历完字典Hash表中节点数据后,释放迭代器时会继续调用dictFingerprint函数计算字典的指纹值,并与首次拿到的指纹值比较,不相等则输出异常”===ASSERTION FAILED===”,且退出程序执行。
- 安全迭代器,遍历的同时删除数据:安全迭代器和普通迭代器迭代数据原理类似,也是通过循环调用dictNext函数依次遍历字典中Hash表的节点。安全迭代器确保读取数据的准确性,不是通过限制字典的部分操作来实现的,而是通过限制rehash的进行来确保数据的准确性,因此迭代过程中可以对字典进行增删改查等操作。主要步骤如下:
- 调用dictGetSafeIterator函数初始化一个安全迭代器,此时会把iter->safe值置为1,表示初始化的迭代器为安全迭代器;
- 循环调用dictNext函数依次遍历字典中Hash表的节点,首次遍历时会把字
典中iterators字段进行加1操作,确保迭代过程中渐进式rehash操作会被中断执行; - 当调用dictNext函数遍历完字典Hash表中节点数据后,释放迭代器时会把
字典中iterators字段进行减1操作,确保迭代后渐进式rehash操作能正常进行。
间断遍历
为了解决在海量数据遍历时,造成的短暂的redis不可用。
函数原型为:
1 | unsigned long dictScan(dict *d, |
dictScan函数间断遍历字典过程中会遇到如下3种情况。
1)从迭代开始到结束,散列表没有进行rehash操作。
2)从迭代开始到结束,散列表进行了扩容或缩容操作,且恰好为两次迭代间隔期间完成了rehash操作。
3)从迭代开始到结束,某次或某几次迭代时散列表正在进行rehash操作。
- 遍历过程中始终未遇到rehash操作
每次迭代都没有遇到rehash操作,也就是遍历字典只遇到第1或第2种情况。其实第1种情况,只要依次按照顺序遍历Hash表ht[0]中节点即可,第2种情况因为在遍历的整个过程中,期间字典可能发生了扩容或缩容操作,如果依然按照顺序遍历,则可能会出现数据重复读取的现象.
Redis为了做到不漏数据且尽量不重复数据,统一采用了一种叫作reverse binary iteration的方法来进行间断数据迭代,接下来看下其主要源码实现,迭代的代码如下:
1 | t0 = &(d->ht[0]); |
为了兼容迭代间隔期间可能发生的缩容与扩容操作,每次迭代时都会对v变量(游标值)进行修改,以确保迭代出的数据无遗漏,游标具体变更算法为:
1 | v |= ~m0; |
- 遍历过程中遇到rehash操作
大小两表并存,所以需要从ht[0]和ht[1]中都取出数据,整个遍历过程为:先找到两个散列表中更小的表,先对小的Hash表遍历,然后对大的Hash表遍历,迭代的代码如下:这套算法能满足这样的特点,主要是巧妙地利用了扩容及缩容正好为整数倍增长或减1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20t0 = &d->ht[0];t1 = &d->ht[1];
if (t0->size > t1->size) {
t0 = &d->ht[1];t1 = &d->ht[0];
}
m0 = t0->sizemask;m1 = t1->sizemask;
de = t0->table[v & m0];
while (de) {/*迭代第一张小Hash表*/
next = de->next;
fn(privdata, de);
de = next;
}
do {/*迭代第二张大Hash表*/
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
v |= ~m1;v = rev(v); v++; v = rev(v);
} while (v & (m0 ^ m1));
少的原理,根据这个特征,很容易就能推导出同一个节点的数据扩容/缩容后在新的Hash
表中的分布位置,从而避免了重复遍历或漏遍历。