3.0版本
redis的动态字符串在3.0中的实现如下:
1 | struct sdshdr { |
其中len代表字符串的实际长度,free代表剩余可分配的长度,buf是一个动态数组。
redis之所以这么封装,有以下几点好处:
- 常数复杂度获得字符串长度,即直接sdshdr.len即可;
- 有效防止缓冲区溢出,也就是说sdshdr记录了字符串长度和可用长度,在对字符进行拼接的时候,可以检查实际空间大小。
- 内存分配采用空间预分配和惰性释放策略,能够减少申请和释放内存的操作,减少系统负载。
- buf存储的字符串是二进制安全的(所谓二进制安全,就是不访问不修改存储的二进制串,而传统的c字符串是通过判断’\0’字符来断定字符串结束,必然涉及到了字符串的访问,是不安全的。)。
- 兼容c字符串函数,可以将sdshr -> buf作为字符串输入到c函数中。
5.0 版本
在3.2版本之前的字符串都如上章节所示,这样能够满足基本的使用了,但是还有没有更好的改进空间呢?
我们从一个简单的问题开始思考:不同长度的字符串是否有必要占用相同大小的头部?一个int占4字节,在实际应用中,存放于Redis中的字符串往往没有这么长,每个字符串都用4字节存储未免太浪费空间了。我们考虑三种情况:短字符串,len和free的长度为1字节就够了;长字符串,用2字节或4字节;更长的字符串,用8字节。
这样确实更省内存,但依然存在以下问题。
问题1:如何区分这3种情况?
问题2:对于短字符串来说,头部还是太长了。以长度为1字节的
字符串为例,len和free本身就占了2个字节,能不能进一步压缩呢?
对于问题1,我们考虑增加一个字段flags来标识类型,用最小的1
字节来存储,且把flags加在柔性数组buf之前,这样虽然多了1字节,
但通过偏移柔性数组的指针即能快速定位flags,区分类型,也可以接
受;对于问题2,由于len已经是最小的1字节了,再压缩只能考虑用位
来存储长度了。
结合两个问题,5种type(长度1字节、2字节、4字节、8字节、小
于1字节)的SDS至少要用3位来存储类型(23 =8),1个字节8位,剩
余的5位存储长度,可以满足长度小于32的短字符串。在Redis 5.0
中,我们用如下结构来存储长度小于32的短字符串:
1 | /* Note: sdshdr5 is never used, we just access the flags byte directly. |
1)len :表示buf中已占用字节数。
2)alloc :表示buf中已分配字节数,不同于free,记录的是为
buf分配的总长度。
3)flags :标识当前结构体的类型,低3位用作标识位,高5位预
留。
4)buf :柔性数组,真正存储字符串的数据空间。
sdshdr5结构如下图所示: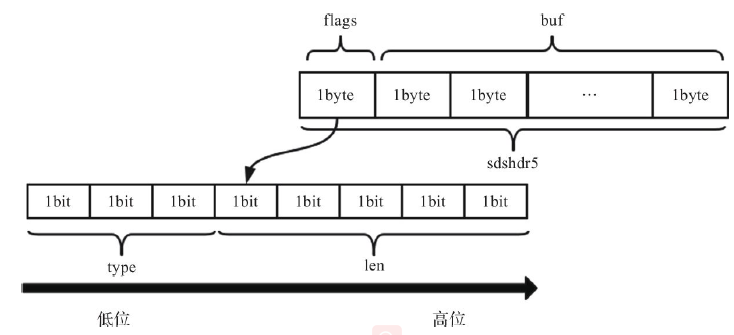
设置flags成员,前三个bits来表示类型,后5个字节表示长度,最多能够表示0~31(2^5)。
而长度大于31的字符串,1个字节依然存不下。我们按之前的思
路,将len和free单独存放。sdshdr8、sdshdr16、sdshdr32和
sdshdr64的结构相同。下面是sds16的结构:
这里为什么使用__attribute__ ((packed))关键字不进行内存对齐呢?
- 节省内存
- SDS返回给上层的,不是结构体首地址,而是指向内容的buf指针。因为此时按1字节对齐,故SDS创建成功后,无论是sdshdr8、sdshdr16还是sdshdr32,都能通过(char*)sh+hdrlen得到buf指针地址(其中hdrlen是结构体长度,通过sizeof计算得到)。修饰后,无论是sdshdr8、sdshdr16还是sdshdr32,都能通过buf[-1]找到flags,因为此时按1字节对齐。若没有packed的修饰,还需要对不同结构进行处理,实现更复杂。
扩容机制
由于5.0版本的动态字符串通过不同的结构体实现,因此当涉及到修改动态字符串的相关操作时,可能需要更改类型。并且动态数组的增长也涉及了扩容机制。
扩容机制保留了3.0版本的惰性释放原则。
应用
- 缓存功能:String字符串是最常用的数据类型,不仅仅是Redis,各个语言都是最基本类型,因此,利用Redis作为缓存,配合其它数据库作为存储层,利用Redis支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
- 计数器:许多系统都会使用Redis作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
- 共享用户Session:用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。大大提高效率。