底层结构:hashtable
unordered set/map底层是以hashtable为数据结构,任何对象/类都可以折射成一个数值(类对象都是由数据构成,对数据进行一些操作然后hash就可以转化成一个数值).
在空间充足的情况下如果hashtable足够长,那么冲突可以大大降低,但是现实中常常采用的是hashtable长度为M,N为数据量,只要M>N即可。
常见的hashtable解决碰撞的方法:
例如,已知哈希表长度m=11,哈希函数为:H(key)= key % 11,则H(47)=3,H(26)=4,H(60)=5,假设下一个关键字为69,则H(69)=3,与47冲突。
线性探测再散列
dii=1,2,3,…,m-1
这种方法的特点是:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。如果用线性探测再散列处理冲突,下一个哈希地址为H1=(3 + 1)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 + 2)% 11 = 5,还是冲突,继续找下一个哈希地址为H3=(3 + 3)% 11 = 6,此时不再冲突,将69填入5号单元。
二次探测再散列
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
这种方法的特点是:冲突发生时,在表的左右进行跳跃式探测,比较灵活。
如果用二次探测再散列处理冲突,下一个哈希地址为H1=(3 + 12)% 11 = 4,仍然冲突,再找下一个哈希地址为H2=(3 - 12)% 11 = 2,此时不再冲突,将69填入2号单元。
伪随机探测再散列
di=伪随机数序列。
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。
如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元。
再hash
这种方法是同时构造多个不同的哈希函数:Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
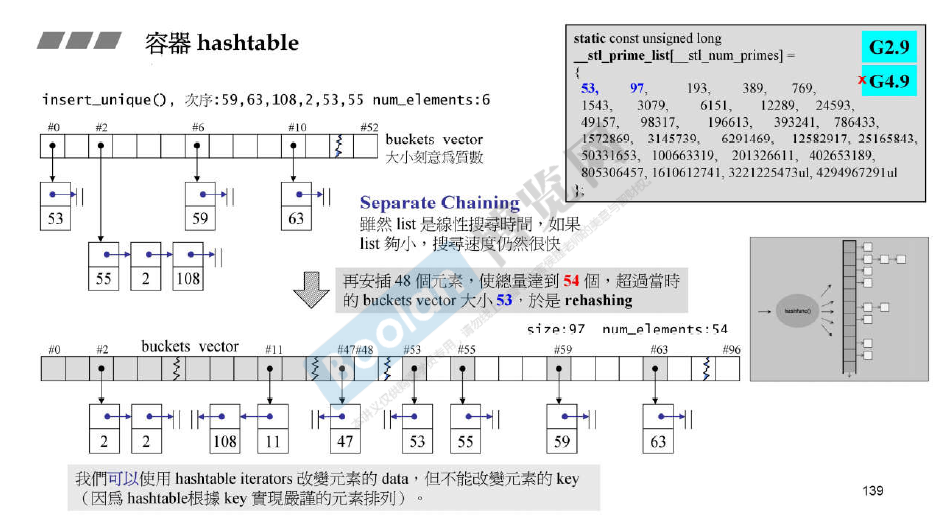
STL的hashtable使用链表法,hashtable的容量大小预先定义好,是一串素数串。当数据量超过hashtable容量之后,会进行rehashing操作,将所有数据再次进行hash操作,放入新的hashtable。
迭代器
hashtable的迭代器也是利用指针,来模拟顺序的遍历操作。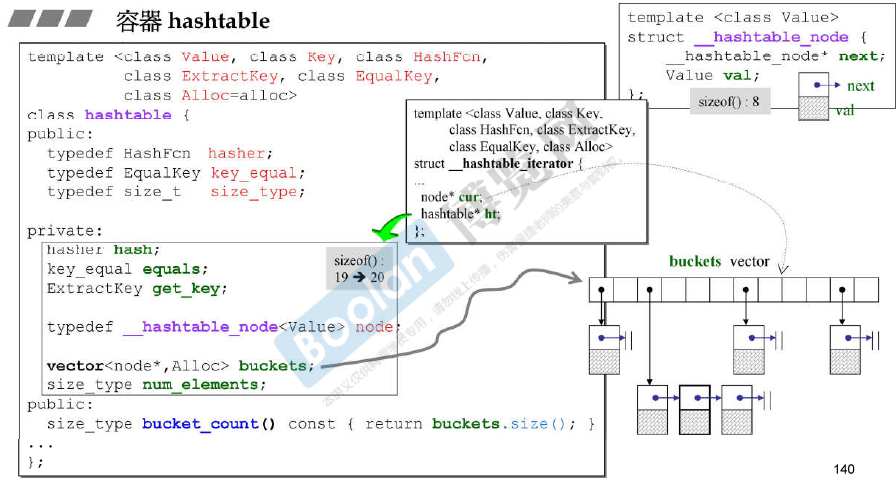
迭代器中存储的是当前node的指针和当前hash bucket的编号。
hash操作
STL中使用模板的特化和泛化来hash。STL对内置类型进行了特化,如果需要对自定义类型进行hash,需要写对应的模板函数特化版本。
