进程
一个普遍的定义
- 进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
上面的定义应该是比较广泛的一种定义,但是定义地非常模糊,也不好理解究竟在操作系统中进程是什么。下面以Linux操作系统为例,说明究竟在操作系统中进程以什么方式存在。
进程资源集合
进程由什么资源组成?在Linux下大概有下面这些:
- 可执行程序代码
- 打开的文件
- 挂起的信号
- 内核内部数据
- 处理器状态
- 一个或者多个具有内存映射的内存地址空间
- 一个或多个执行线程
- 存放全局变量的数据段
进程描述符
在Linux系统中内核把进程的列表存放在叫做任务队列(个人理解就是一个不同优先级的双向循环链表)的结构中,每一项类型为task_struct,称为进程描述符。进程描述符通过slab分配器分配。
Q:什么是slab?
A:
- 使用传统分配的缺点:传统的内存分配算法通过伙伴系统分配,伙伴系统使用的是多级链表来实现,分配策略就是从小到大找最适合的链表,这种分配很容易造成内部碎片,特别是task_struct这种小对象。
- 分配流程:当用户进程或者系统进程向SLAB申请了专门存放某一类对象的内存空间,但此时SLAB中没有足够的空间来专门存放此类对象,于是SLAB就像伙伴系统申请2的幂次方个连续的物理页框,SLAB的申请得到伙伴系统满足之后,SLAB就对这一块内存进行管理,用以存放多个上文中提到的某一类对象。对象实际上指的是某一种数据类型。一个SLAB只针对一种数据类型(对象)。为了提升对对象的访问效率,SLAB可能会对对象进行对齐。为了提升效率,SLAB分配器为每一个CPU都提供了每CPU数据结构struct array_cache,该结构指向被释放的对象。当CPU需要使用申请某一个对象的内存空间时,会先检查array_cache中是否有空闲的对象,如果有的话就直接使用。如果没有空闲对象,就像SLAB分配器进行申请。
- 说明:上面说明的缓存指的并不是真正的缓存,真正的缓存指的是硬件缓存,也就是我们通常所说的L1 cache、L2 cache、L3 cache,硬件缓存是为了解决快速的CPU和速度较慢的内存之间速度不匹配的问题,CPU访问cache的速度要快于内存,如果将常用的数据放到硬件缓存中,使用时CPU直接访问cache而不用再访问内存,从而提升系统速度。下文中的缓存实际上是用软件在内存中预先开辟一块空间,使用时直接从这一块空间中去取,是SLAB分配器为了便于对小块内存的管理而建立的。
分配的进程结构体如下图所示: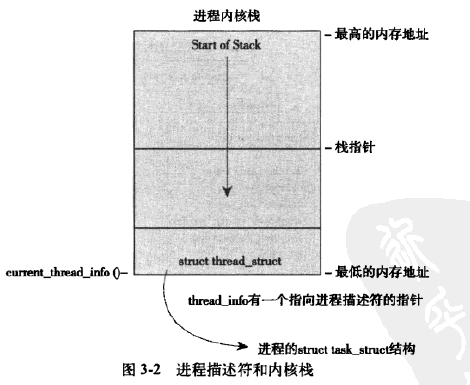
每个任务的thread_info结构在内核栈的尾端分配,结构中task域存放的是指向任务的实际的task_struct指针。
内核通过进程描述符pid在标识进程,最大默认32768(为了兼容旧版本),在X86系统中通过栈指针屏蔽来计算thread_info偏移,汇编如下:
1 | movl $-8192, %eax |
附X86常用寄存器表。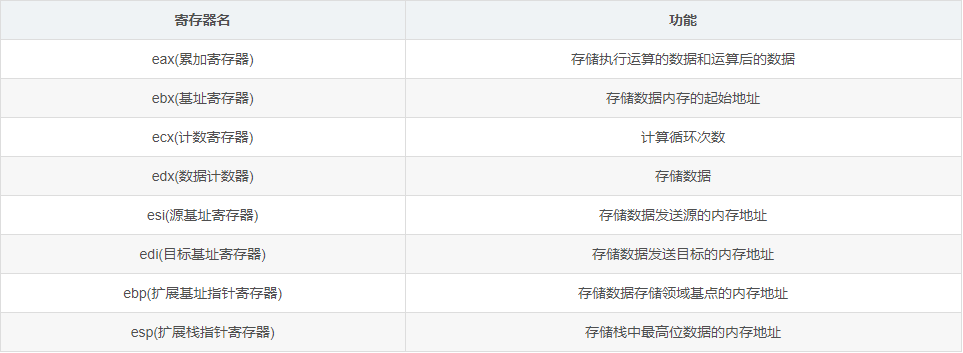
进程状态
一图胜千言: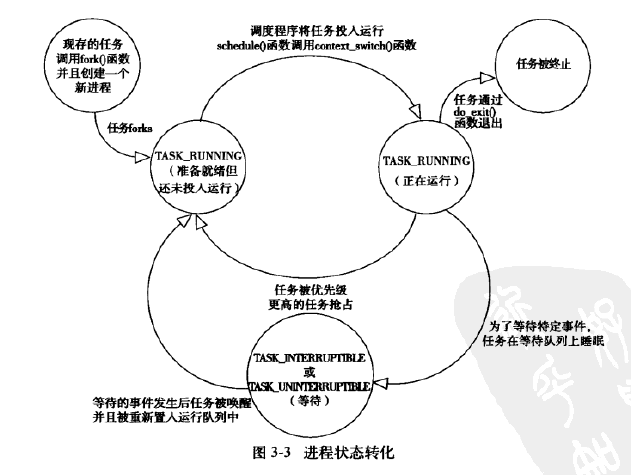
进程上下文
进程上下文是进程执行活动全过程的静态描述。我们把已执行过的进程指令和数据在相关寄存器与堆栈中的内容称为进程上文,把正在执行的指令和数据在寄存器与堆栈中的内容称为进程正文,把待执行的指令和数据在寄存器与堆栈中的内容称为进程下文。
实际上linux内核中,进程上下文包括进程的虚拟地址空间和硬件上下文。
- 虚拟地址上下文切换
在进程描述符中有mm_struct结构体来描述进程地址空间,这个结构体中有一个成员pgd,保存的是进程的页的全局目录的虚拟地址,是在fork()的时候(此处应该是写时复制是赋值的,直接fork会共用父进程的地址)设置的。
代码trace如下:1
2
3
4
5
6
7context_switch // kernel/sched/core.c
->switch_mm_irqs_off
->switch_mm
->__switch_mm
->check_and_switch_context
->cpu_switch_mm
->cpu_do_switch_mm(virt_to_phys(pgd),mm) //arch/arm64/include/asm/mmu_context.h代码中最核心的为181行,最终将进程的pgd虚拟地址转化为物理地址存放在ttbr0_el1中,这是用户空间的页表基址寄存器,当访问用户空间地址的时候mmu会通过这个寄存器来做遍历页表获得物理地址(ttbr1_el1是内核空间的页表基址寄存器,访问内核空间地址时使用,所有进程共享,不需要切换)。完成了这一步,也就完成了进程的地址空间切换,确切的说是进程的虚拟地址空间切换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28arch/arm64/mm/proc.S
158 /*
159 * cpu_do_switch_mm(pgd_phys, tsk)
160 *
161 * Set the translation table base pointer to be pgd_phys.
162 *
163 * - pgd_phys - physical address of new TTB
164 */
165 ENTRY(cpu_do_switch_mm)
166 mrs x2, ttbr1_el1
167 mmid x1, x1 // get mm->context.id
168 phys_to_ttbr x3, x0
169
170 alternative_if ARM64_HAS_CNP
171 cbz x1, 1f // skip CNP for reserved ASID
172 orr x3, x3, #TTBR_CNP_BIT
173 1:
174 alternative_else_nop_endif
175
176 bfi x3, x1, #48, #16 // set the ASID field in TTBR0
177
178 bfi x2, x1, #48, #16 // set the ASID
179 msr ttbr1_el1, x2 // in TTBR1 (since TCR.A1 is set)
180 isb
181 msr ttbr0_el1, x3 // now update TTBR0
182 isb
183 b post_ttbr_update_workaround // Back to C code...
184 ENDPROC(cpu_do_switch_mm) - 硬件上下文切换
将结构中的cpu寄存器信息重新设置给当前cpu即可。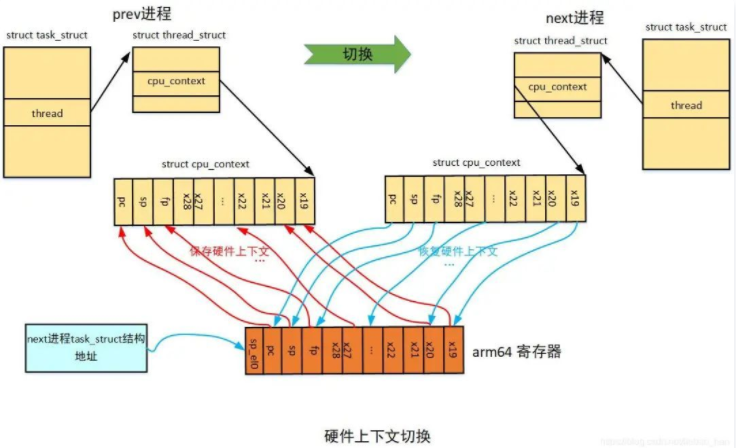
线程
线程拥有独立的程序计数器,进程栈和一组进程寄存器。内核调度的对象是线程,而不是进程。一个进程可以包含多个线程,最少有一个线程。
为啥要线程
一句话来说,就是避免进程间切换的上下文转换开销。进程上下文需要虚拟空间转换,硬件寄存器上下文转换,但是在同一个进程中的线程的资源基本上是共享的,切换的开销基本可以忽略不计,因此有更高的效率。
Linux中的线程
在内核角度,没有线程这个概念,线程是由进程实现的。线程仅仅是和其他进城共享某些资源的进程。
创建线程
在Linux中创建线程和进程最终都是调用clone()系统调用,不过进程是:
1 | clone(SIGCHLD, 0); |
而线程需要共享地址空间,文件系统资源,文件描述符和信号处理程序。如:
1 | clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0); |