简介
参考tcmalloc github官方文档
TCMalloc 是一种内存分配器,旨在替代系统默认分配器,具有以下特点:
可以实现大多数对象的快速、无竞争的分配和释放。 对象被缓存,具体取决于模式,每个线程或每个逻辑 CPU。 大多数分配不需要锁定,因此多线程应用程序争用少,扩展性好。
灵活使用内存,因此释放的内存可以重新用于不同的对象大小,或返回给操作系统。
通过分配相同大小的对象的“页面”来降低每个对象的内存开销。小对象的空间损耗很少。
低开销采样,可以详细了解应用程序内存使用情况。
下面的框图显示了 TCMalloc 的粗略内部结构: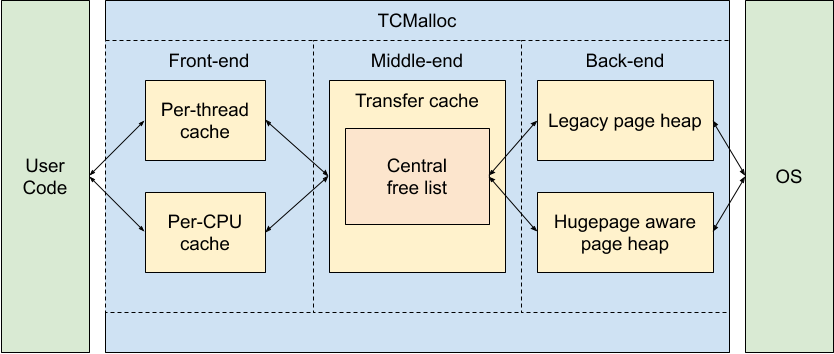
我们可以将 TCMalloc 分解为三个组件。前端、中端和后端。职责的粗略分解是:
前端是一个缓存,为应用程序提供快速的内存分配和释放。
中端负责重新填充前端缓存。
后端处理从操作系统获取内存。
请注意,前端可以在 per-CPU 或 legacy per-thread 模式下运行,后端可以支持大页面感知 pageheap 或 legacy pageheap。
数据结构
freelist是tcmalloc的实现基础,只不过tcmalloc采用了三层的架构:TreadCache、CentralCache、PageHeap。每一级的分配单元的粒度不一样。基本的原理就是:分配内存和释放内存都是按照从前到后的顺序,在各个层次中进行尝试,前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
- tcmalloc有三个层次:
- TreadCache, 这个内存池是线程私有的, 每个线程一份. 每个线程首先会从这里请求内存. 由于是线程私有的, 不需要加锁同步, 所以非常高效. TreadCache维护一组不同类型的freelist, 基本单位是object, 为了实现变长内存的申请, object预设了一些规格(class), 比如8, 16, 32, 80等等
- CentralCache, 这是第二层线程池, 这是全局的, 当线程在本地请求失败时会从这里请求object. CentralCache也维护一组关联obejct规格的freelist, 基本单位是span, span由多个连续page(物理单位)组成, 可以分隔为多个object(逻辑单位)。
- Pageheap, 这是第三层, 当无法从CentralCache获取到内存时, 会从Pageheap中请求span. 如果PageHeap也没有内存, 则向操作系统请求. Pageheap根据page的数量维护一组freelist, 基本单位是span. 另外还维护这page到span的映射关系.
- 小对象和大对象: 大于256kb的称为大对象, 大对象会直接向Pageheap申请span, 小对象的申请则需要经过TreadCache申请。
- 粒度: tcmalloc, 有两种粒度的内存, object和span. TreadCache维护的粒度是object, PageHeap维护的粒度是span. 而CentralCache是一个中间者, 维护span到object的映射关系.
数据结构概览如图所示: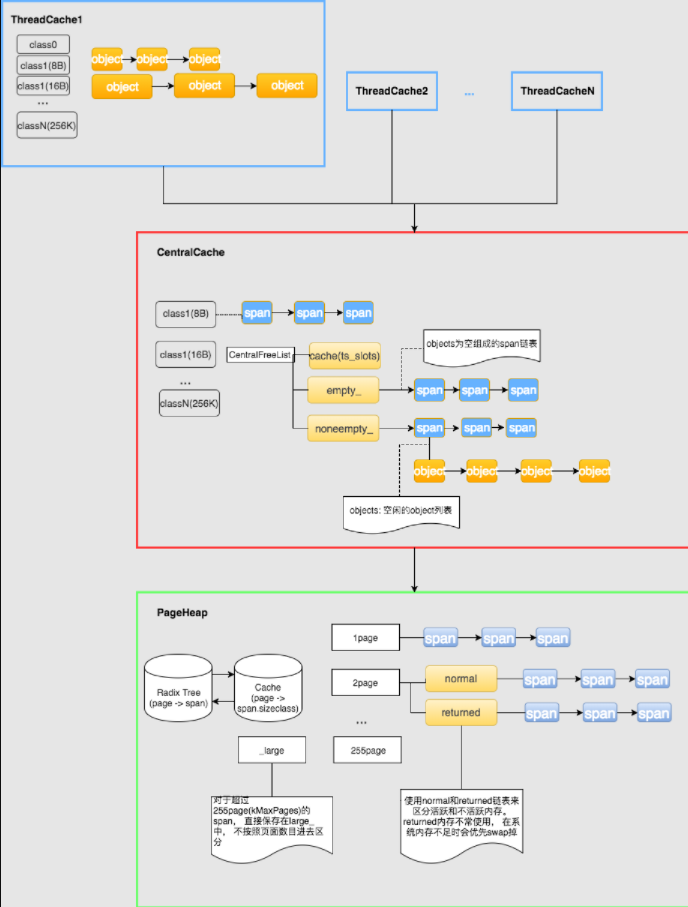
- TreadCache
线程本地缓存, 比较简单, 维护一组freelist, 尺寸小于256K的小对象, 均由它进行分配. 分配过程中不需要加锁1
2
3
4class ThreadCache {
private:
FreeList list_[kNumClasses];
}; - CentralCache
对应不同class的object, CentralCache中有多个CentralFreeList. CentralFreeList维护的是span链表, 每个span下有根据object的大小切割组成一个object链. objects链表示未被分配的object, 分配出去的object数量使用span.refcount_ 记录. span 的结构如下:CentralFreeList的结构:1
2
3
4
5
6
7
8
9
10
11
12
13struct Span {
PageID start; // Span描述的内存的起始地址
Length length; // Span页面数量
Span* next; // Span由双向链表组成,PageHeap和CentralFreeList中都用的到
Span* prev; //
void* objects; // Span会在CentralFreeList中拆分成由object组成的free list
unsigned int refcount : 16; // Span的object被引用次数,当refcount=0时,表示此Span没有被使用
unsigned int sizeclass : 8; // Span属于的size class
unsigned int location : 2; // Span在的位置IN_USE?normal?returned?
unsigned int sample : 1; // Sampled object?
// What freelist the span is on: IN_USE if on none, or normal or returned
enum { IN_USE, ON_NORMAL_FREELIST, ON_RETURNED_FREELIST };
};CentralFreeList里有两个span链表:nonempty_和empty_,根据span的objects链是否有空闲,放入对应链表。1
2
3
4
5
6
7class CentralFreeList {
private:
SpinLock lock_; //控制线程访问的锁
size_t size_class_; // span对应object的size class, 同上
Span empty_; // 放置没有空闲空间的span, 可以避免查找这部分span
Span nonempty_; // 和empty相对
};
CentralFreeList里面还有一个cache(tc_slots_),回收回来的一批object先放进cache,存不下了再回收进span的objects链。分配object给ThreadCache时也是先尝试在cache里面拿,没了再去span里面分配。
TreadCache一般都是以batch_size为一个批次像CentralCache请求, 而为了cache的简单高效,如果批次个数不等于batch_size,则会绕过cache。
- Pageheap
整体结构如下图所示: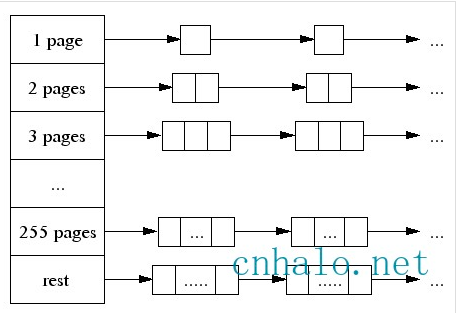
数组中第256个元素是所有大于255个页面都挂到该链表中.用多种定长 Page 来实现变长 Page 的分配,初始时只有 255 Page 的 Span,如果要分配 1 个 Page 的 Span,就把这个 Span 分裂成两个,1 + 254,把254再记录下来。对于 Span 的回收,需要考虑Span的合并问题,否则在分配回收多次之后,就只剩下很小的 Span 了,也就是带来了外部碎片 问题。
- page维护了两样东西: page -> span的映射关系和空闲的span伙伴系统.
page -> span 映射
page到span的映射关系通过radix 树来实现, 当释放一段内存时, 通过内存偏移和对齐, 就能计算出对应的page, 拿到page在radix树中查找到对应的span, 拿到span就拿到了sizeclass, 从而可以在CentralCache定位span, 将释放的object添加到span的objects链表. 另外通过radix树还可以找到span的相邻span, 如果相邻的span空闲, 则会合并他们。伙伴系统(span freelist)
span的尺寸有从1个page到255个page的所有规格, 大于255个page的span单独归为一类,不作细分. PageHeap维护了这些不同规格的freelist:1
2
3
4
5
6struct SpanList {
Span normal;
Span returned;
};
SpanList large_; // 超过256k的span链表
SpanList free_[kMaxPages]在内存分配时, 会根据span的大小在伙伴系统中查找, 如果没有空闲的span时, 会向上层更大尺寸的span链表请求, 再没有, 就需要向系统申请了. span可以根据需要不断组合和分割.
freelist其实是有两个链,normal和returned,以区别活跃跟不活跃的内存。
PageHeap并不会将内存释放给kernel,因为它们之间的交互都是针对一批连续page的,要想回收到整批的page,可能性很小。在PageHeap里面,多余的内存会放到returned里面去,跟normal做一下隔离。这样一来,normal的内存总是优先被使用,kernel倾向于一直保留它们。而returned的内存则不常被使用,kernel在内存不够的时候会优先将它们swap掉。span进入returned时,tcmalloc还附加了一个操作,madvise(MADV_DONTNEED),试图告诉kernel这个内存已经不用了
其实不用returned也能完成这样的事情,因为normal是个链表,每次分配回收总是作用在链表头上,那么链表内的span本身就按从热到冷的顺序排序了。链表尾部的span如果长期不被使用,不管是否移动到returned链,kernel都会倾向于将它们swap掉
为减少查询radix tree的开销,PageHeap还维护了一个最近最常使用的若干个page到class(span.sizeclass)的对应关系cache。为了保持cache的效率,cache只提供64K个固定坑位,旧的对应关系会被新来的对应关系替换掉。
分配和回收流程
一图胜千言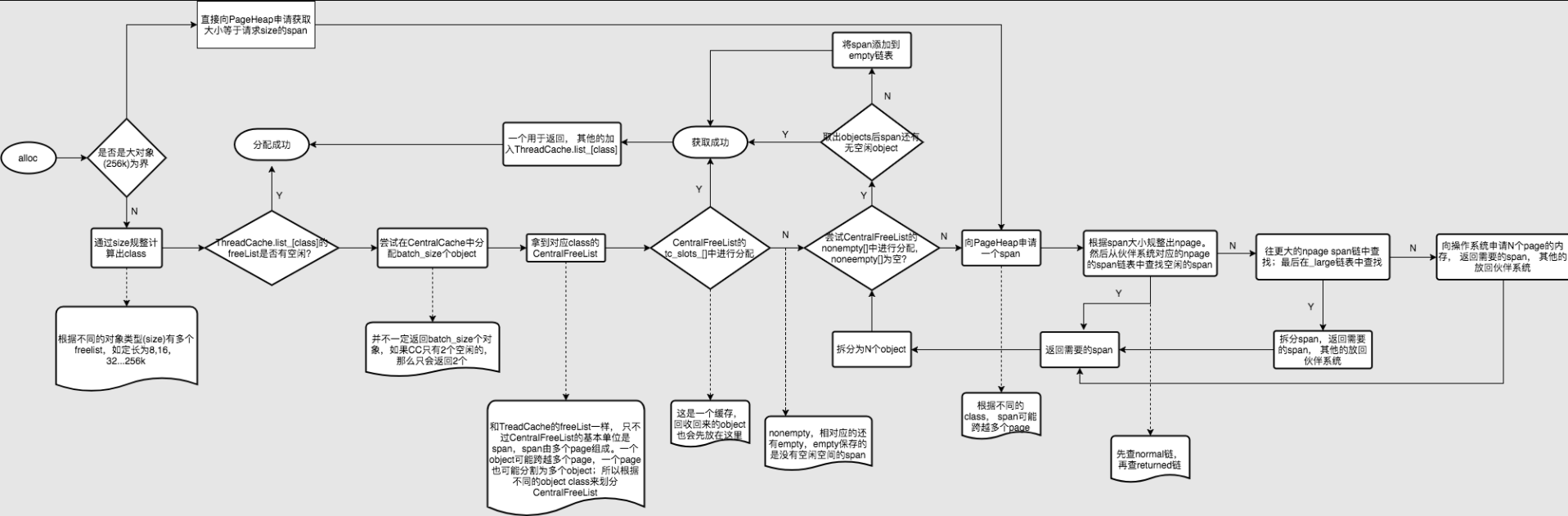

与ptmalloc对比的优点
优点:
- 分配更快.小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。 并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费。
- 占用额外空间少(例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。Ptmalloc2使用最少8字节描述一个chunk。)
- 碎片化控制优越.ThreadCache会阶段性的回收内存到CentralCache里。 解决了ptmalloc2中arena之间不能迁移的问题。