简介
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。具体细节可以参考 Jason Evans 发表的论文 《A Scalable Concurrent malloc Implementation for FreeBSD》。
架构设计
了解了vc6内存管理、ptmalloc、tcmalloc之后,jemalloc理解起来就轻松了不上,因为jemalloc有些地方借鉴了tcmalloc,先pull出整体架构图: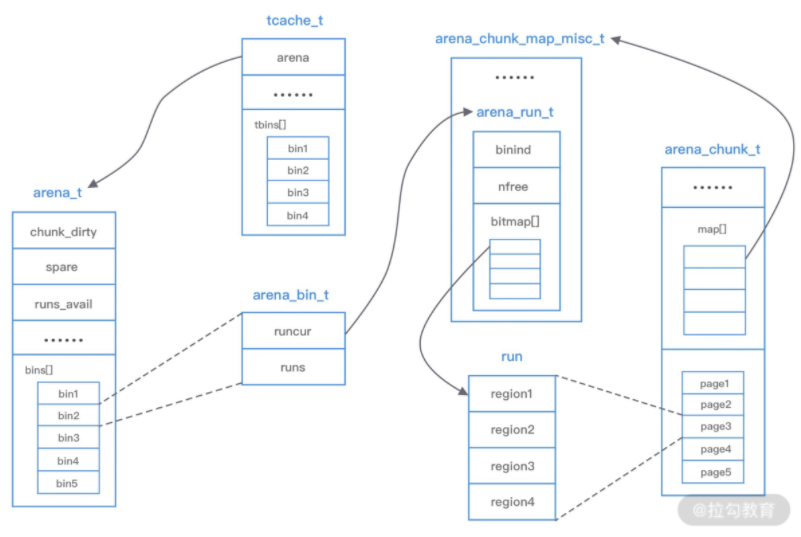
图中涉及 jemalloc 的几个核心概念,例如 arena、bin、chunk、run、region、tcache 等,我们下面逐一进行介绍。
- arena 是 jemalloc 最重要的部分,内存由一定数量的 arenas 负责管理。每个用户线程都会被绑定到一个 arena 上,线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配,为了减少线程之间的锁竞争,默认每个 CPU 会分配 4 个 arena。
- bin 用于管理不同档位的内存单元,每个 bin 管理的内存大小是按分类依次递增。因为 jemalloc 中小内存的分配是基于 Slab 算法完成的,所以会产生不同类别的内存块。
- chunk 是负责管理用户内存块的数据结构,chunk 以 Page 为单位管理内存,默认大小是 4M,即 1024 个连续 Page。每个 chunk 可被用于多次小内存的申请,但是在大内存分配的场景下只能分配一次。
- run 实际上是 chunk 中的一块内存区域,每个 bin 管理相同类型的 run,最终通过操作 run 完成内存分配。run 结构具体的大小由不同的 bin 决定,例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块进行分配。
- region 是每个 run 中的对应的若干个小内存块,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发。
- tcache 是每个线程私有的缓存,用于 small 和 large 场景下的内存分配,每个 tcahe 会对应一个 arena,tcache 本身也会有一个 bin 数组,称为tbin。与 arena 中 bin 不同的是,它不会有 run 的概念。tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,从而避免锁竞争,如果分配失败才会通过 run 执行内存分配。
jemalloc 的几个核心的概念介绍完了,我们再重新梳理下它们之间的关系:
- 内存是由一定数量的 arenas 负责管理,线程均匀分布在 arenas 当中;
- 每个 arena 都包含一个 bin 数组,每个 bin 管理不同档位的内存块;
- 每个 arena 被划分为若干个 chunks,每个 chunk 又包含若干个 runs,每个 run 由连续的 Page 组成,run 才是实际分配内存的操作对象;
- 每个 run 会被划分为一定数量的 regions,在小内存的分配场景,region 相当于用户内存;
- 每个 tcache 对应 一个 arena,tcache 中包含多种类型的 bin。
首先讲下 Samll 场景,如果请求分配内存的大小小于 arena 中的最小的 bin,那么优先从线程中对应的 tcache 中进行分配。首先确定查找对应的 tbin 中是否存在缓存的内存块,如果存在则分配成功,否则找到 tbin 对应的 arena,从 arena 中对应的 bin 中分配 region 保存在 tbin 的 avail 数组中,最终从 availl 数组中选取一个地址进行内存分配,当内存释放时也会将被回收的内存块进行缓存。
Large 场景的内存分配与 Samll 类似,如果请求分配内存的大小大于 arena 中的最小的 bin,但是不大于 tcache 中能够缓存的最大块,依然会通过 tcache 进行分配,但是不同的是此时会分配 chunk 以及所对应的 run,从 chunk 中找到相应的内存空间进行分配。内存释放时也跟 samll 场景类似,会把释放的内存块缓存在 tacache 的 tbin 中。此外还有一种情况,当请求分配内存的大小大于tcache 中能够缓存的最大块,但是不大于 chunk 的大小,那么将不会采用 tcache 机制,直接在 chunk 中进行内存分配。
Huge 场景,如果请求分配内存的大小大于 chunk 的大小,那么直接通过 mmap 进行分配,调用 munmap 进行回收。