linux进程地址空间
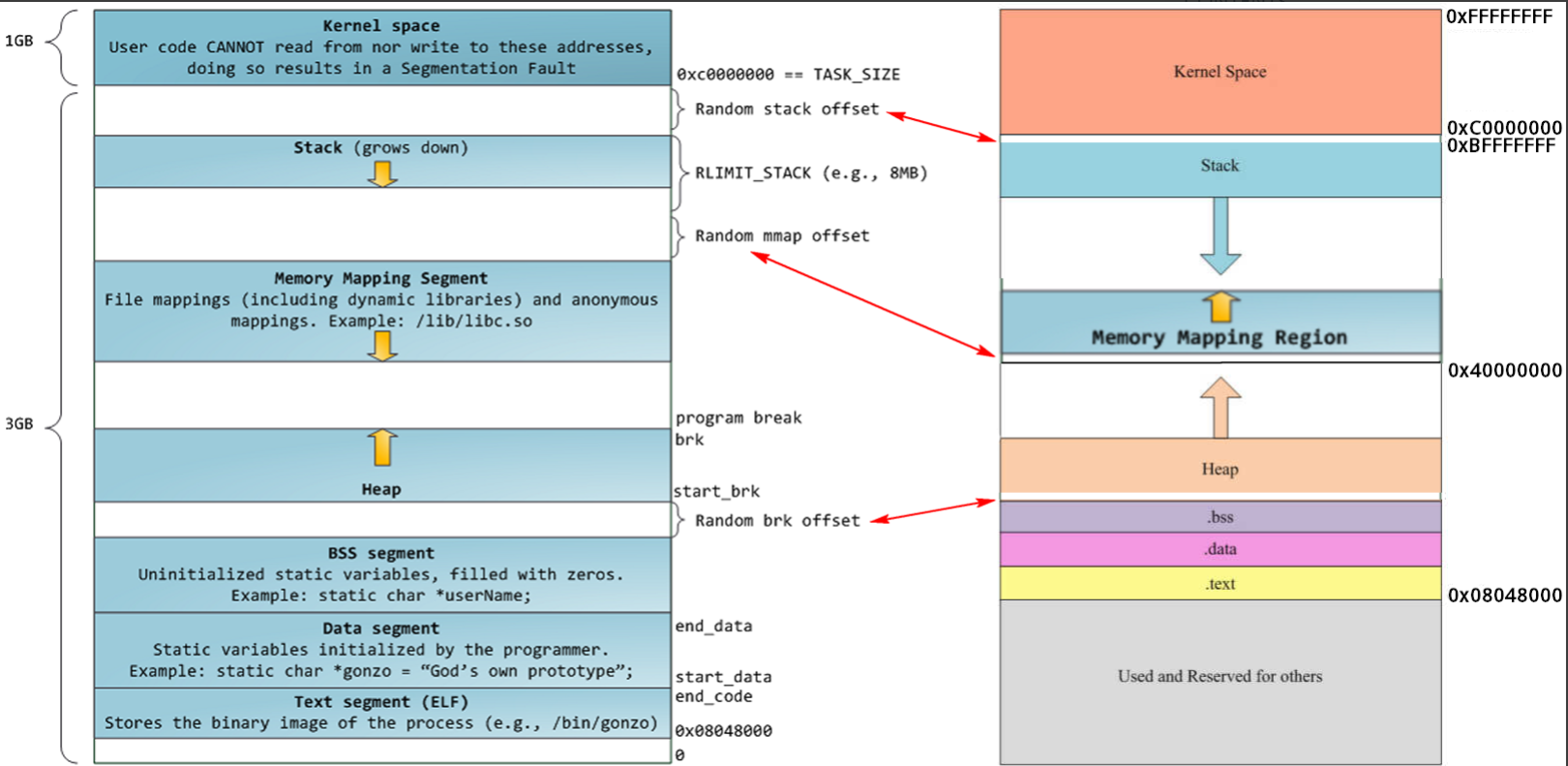
如上图所示在一个32位系统中,可寻址的空间大小是4G,linux系统下0-3G是用户模式,3-4G是内核模式。而在用户模式下又分为代码段、数据段、.bss段、堆、栈。其中代码段主要存放进程的可执行二进制代码,字符串字面值和只读变量。数据段存放已经初始化且初始值非0的全局变量和局部静态变量。bss段则存放未初始化或初始值为0的全局变量和局部静态变量。而堆段则是存放由用户动态分配内存存储的变量。栈段则主要存储局部变量、函数参数、返回地址等。
bss段、数据段和代码段是可执行程序编译时的分段,运行时还需要栈和堆。将应用程序加载到内存空间执行时,操作系统负责代码段、数据段和bss段的加载,并在内存中为这些段分配空间。栈也由操作系统分配和管理而堆则是由程序员自己管理。
malloc内存单元
chunk结构体
1
2
3
4
5
6
7
8
9
10
11
12struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
源码注释写到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/*
Chunks of memory are maintained using a `boundary tag' method as
described in e.g., Knuth or Standish. (See the paper by Paul
Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a
survey of such techniques.) Sizes of free chunks are stored both
in the front of each chunk and at the end. This makes
consolidating fragmented chunks into bigger chunks very fast. The
size fields also hold bits representing whether chunks are free or
in use.
An allocated chunk looks like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if allocated | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
*/大概意思就是使用了boundary tag技术,也就是free block上下两端加cookie,还记得vc6和STL的allocator章节的图,就像下面这样。
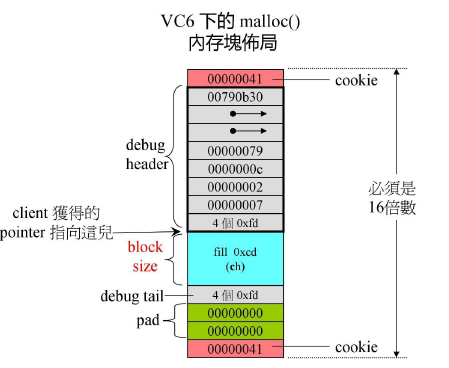
注释中继续描述了chunk的组织方式——双向链表.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/*
Free chunks are stored in circular doubly-linked lists, and look like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
*/我们看一下结构体中的变量。
- prev_size:如果前一个chunk是空闲的,该域表示前一个chunk的大小,如果前一个chunk不空闲,该域无意义。注意:这里的前一个指的是存储物理相邻地址较低的那一个chunk。
- size:该 chunk 的大小,大小必须是 2 SIZE_SZ 的整数倍。如果申请的内存大小不是 2 SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示:
- A: NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程(分配区/arena),1表示不属于,0表示属于。
- M: IS_MAPPED,他表示当前chunk是从哪个内存区域获得的虚拟内存。M为1表示该chunk是从mmap映射区域分配的,否则是从heap区域分配的。
- P: PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的P位都会被设置为1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲chunk之间的合并。
- fd,bk: chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk
- bk 指向上一个(非物理相邻)空闲的 chunk
- fd_nextsize, bk_nextsize:也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize指向下一个比当前chunk size小的第一个空闲chunk,不包含 bin 的头指针。
- bk_nextszie指向上一个比当前chunk size大的第一个空闲chunk,不包含 bin 的头指针。
- large bins中的空闲chunk是按照大小排序的。这样做可以避免在寻找合适chunk 时挨个遍历。
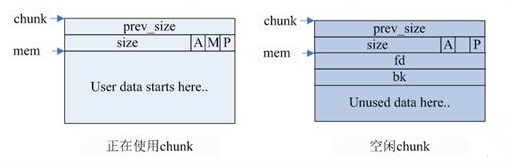
上图展示了chunk分配前后的变化,利用了嵌入式指针技术,这个技术在VC6和STL allocator中应用也很多。
linux内存分配
linux下可以使用系统调用
mmap:内核将硬盘文件的内容直接映射到内存,任何应用程序都可通过 Linux 的 mmap() 系统调用请求这种映射。
- 内存映射是一种方便高效的文件 I/O 方式, 因而被用于装载动态共享库。
- 用户也可创建匿名内存映射,该映射没有对应的文件,可用于存放程序数据。
- 在 Linux 中,若通过 malloc() 请求一大块内存,C 运行库将创建一个匿名内存映射,而不使用堆内存。“大块”意味着比阈值MMAP_THRESHOLD还大,缺省为 128KB,可通过 mallopt() 调整。
- mmap 映射区向下扩展,堆向上扩展,两者相对扩展,直到耗尽虚拟地址空间中的剩余区域。
sbrk() 或brk():start_brk和brk分别是堆的起始和终止地址,我们使用malloc动态分配的内存就在这之间。我们可以使用系统调用sbrk() 或brk()增加brk的值,达到增大堆空间的效果,但是系统调用代价太大,涉及到用户态和内核态的相互转换。所以,实际中系统分配较大的堆空间,进程通过malloc()库函数在堆上进行空间动态分配,堆如果不够用malloc可以进行系统调用,增大brk的值。
- 两个系统调用的源码为: brk函数将break指针直接设置为某个地址,而sbrk将break指针从当前位置移动increment所指定的增量。brk在执行成功时返回0,否则返回-1并设置errno为ENOMEM;sbrk成功时返回break指针移动之前所指向的地址,否则返回(void *)-1。
1
2
3
int brk(void *addr);
void *sbrk(intptr_t increment);
如果将increment设置为0,则可以获得当前break的地址。另外需要注意的是,由于Linux是按页进行内存映射的,所以如果break被设置为没有按页大小对齐,则系统实际上会在最后映射一个完整的页,从而实际已映射的内存空间比break指向的地方要大一些。但是使用break之后的地址是很危险的(尽管也许break之后确实有一小块可用内存地址)。
- 两个系统调用的源码为:
malloc实现
linux下malloc源码分析具体可见《glibc内存管理ptmalloc源代码分析》一书.下面对其思想进行概括,主要掌握其思想,细节实现不在此讨论。
由于brk/sbrk/mmap属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销(即cpu从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态),这是非常影响性能的;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。鉴于此,malloc采用的是内存池的实现方式,malloc内存池实现方式更类似于STL分配器和memcached的内存池,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块即可。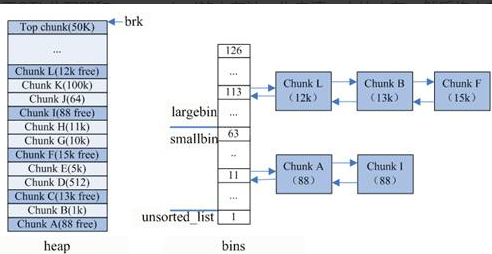
源码注释对bin的大小描述为:
1 | /* |
内存池保存在bins这个长128的数组中,每个元素都是一双向个链表。
- bins[0]目前没有使用
- bins[1]的链表称为unsorted_list,用于维护free释放的chunk。
- bins[2,63)的区间称为small_bins,用于维护<512字节的内存块,其中每个元素对应的链表中的chunk大小相同,均为index*8。
- bins[64,127)称为large_bins,用于维护>512字节的内存块,每个元素对应的链表中的chunk大小不同,index越大,链表中chunk的内存大小相差越大,例如: 下标为64的chunk大小介于[512, 512+64),下标为95的chunk大小介于[2k+1,2k+512)。同一条链表上的chunk,按照从小到大的顺序排列。
malloc将内存分成了大小不同的chunk,然后通过bins来组织起来。 - malloc将相似大小的chunk(图中可以看出同一链表上的chunk大小差不多)用双向链表链接起来,这样一个链表被称为一个bin。malloc一共维护了128个bin,并使用一个数组来存储这些bin。
数组中第一个为unsorted bin,数组编号前2到前64的bin为small bin,同一个small bin中的chunk具有相同的大小,两个相邻的small bin中的chunk大小相差8bytes。small bins后面的bin被称作large bin。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。large bin的每个bin相差64字节。
malloc除了有unsorted bin,small bin,large bin三个bin之外,还有一个fast bin。一般的情况是,程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的 chunk 之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效的,故而,malloc 中在分配过程中引入了 fast bins,不大于 max_fast(默认值为 64B)的 chunk 被释放后,首先会被放到 fast bins中,fast bins 中的 chunk 并不改变它的使用标志 P。这样也就无法将它们合并,当需要给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会在 fast bins 中查找相应的空闲块,然后才会去查找 bins 中的空闲 chunk。在某个特定的时候,malloc 会遍历 fast bins 中的 chunk,将相邻的空闲 chunk 进行合并,并将合并后的 chunk 加入 unsorted bin 中,然后再将 unsorted bin 里的 chunk 加入 bins 中。
unsorted bin 的队列使用 bins 数组的第一个,如果被用户释放的 chunk 大于 max_fast,或者 fast bins 中的空闲 chunk 合并后,这些 chunk 首先会被放到 unsorted bin 队列中,在进行 malloc 操作的时候,如果在 fast bins 中没有找到合适的 chunk,则malloc 会先在 unsorted bin 中查找合适的空闲 chunk,然后才查找 bins。如果 unsorted bin 不能满足分配要求。 malloc便会将 unsorted bin 中的 chunk 加入 bins 中。然后再从 bins 中继续进行查找和分配过程。从这个过程可以看出来,unsorted bin 可以看做是 bins 的一个缓冲区,增加它只是为了加快分配的速度。(其实感觉在这里还利用了局部性原理,常用的内存块大小差不多,从unsorted bin这里取就行了,这个和TLB之类的都是异曲同工之妙啊!)
除了上述四种bins之外,malloc还有三种内存区。
- 当fast bin和bins都不能满足内存需求时,malloc会设法在top chunk中分配一块内存给用户;top chunk为在mmap区域分配一块较大的空闲内存模拟sub-heap。(比较大的时候) >top chunk是堆顶的chunk,堆顶指针brk位于top chunk的顶部。移动brk指针,即可扩充top chunk的大小。当top chunk大小超过128k(可配置)时,会触发malloc_trim操作,调用sbrk(-size)将内存归还操作系统。
- 当chunk足够大,fast bin和bins都不能满足要求,甚至top chunk都不能满足时,malloc会从mmap来直接使用内存映射来将页映射到进程空间,这样的chunk释放时,直接解除映射,归还给操作系统。(极限大的时候)
- Last remainder是另外一种特殊的chunk,就像top chunk和mmaped chunk一样,不会在任何bins中找到这种chunk。当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。(这个应该是fast bins中也找不到合适的时候,用于极限小的)
我们再来看这个分配前后的图:
由之前的分析可知malloc利用chunk结构来管理内存块,malloc就是由不同大小的chunk链表组成的。malloc会给用户分配的空间的前后加上一些控制信息,用这样的方法来记录分配的信息,以便完成分配和释放工作。chunk指针指向chunk开始的地方,图中的mem指针才是真正返回给用户的内存指针。
- chunk 的第二个域的最低一位为P,它表示前一个块是否在使用中,P 为 0 则表示前一个 chunk 为空闲,这时chunk的第一个域 prev_size 才有效,prev_size 表示前一个 chunk 的 size,程序可以使用这个值来找到前一个 chunk 的开始地址。当 P 为 1 时,表示前一个 chunk 正在使用中,prev_size程序也就不可以得到前一个 chunk 的大小。不能对前一个 chunk 进行任何操作。malloc分配的第一个块总是将 P 设为 1,以防止程序引用到不存在的区域。
- Chunk 的第二个域的倒数第二个位为M,他表示当前 chunk 是从哪个内存区域获得的虚拟内存。M 为 1 表示该 chunk 是从 mmap 映射区域分配的,否则是从 heap 区域分配的。
- Chunk 的第二个域倒数第三个位为 A,表示该 chunk 属于主分配区或者非主分配区,如果属于非主分配区,将该位置为 1,否则置为 0。
当chunk空闲时,其M状态是不存在的,只有AP状态,原本是用户数据区的地方存储了四个指针,指针fd指向后一个空闲的chunk,而bk指向前一个空闲的chunk,malloc通过这两个指针将大小相近的chunk连成一个双向链表。在large bin中的空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
malloc步骤
malloc 内存分配流程
- 如果分配内存<512字节,则通过内存大小定位到smallbins对应的index上(floor(size/8)).
- 如果smallbins[index]为空,进入步骤3.
- 如果smallbins[index]非空,直接返回第一个chunk.
- 如果分配内存>512字节,则定位到largebins对应的index上.
- 如果largebins[index]为空,进入步骤3.
- 如果largebins[index]非空,扫描链表,找到第一个大小最合适的chunk,如size=12.5K,则使用chunk B,剩下的0.5k放入unsorted_list中
- 遍历unsorted_list,查找合适size的chunk,如果找到则返回;否则,将这些chunk都归类放到smallbins和largebins里面.
- index++从更大的链表中查找,直到找到合适大小的chunk为止,找到后将chunk拆分,并将剩余的加入到unsorted_list中.
- 如果还没有找到,那么使用top chunk.
- 内存<128k,使用brk;内存>128k,使用mmap获取新内存.
注意事项
- 调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
- 虚拟内存并不是每次malloc后都增长,是与上一节说的堆顶没发生变化有关,因为可重用堆顶内剩余的空间,这样的malloc是很轻量快速的。
- 如果虚拟内存发生变化,基本与分配内存量相当,因为虚拟内存是计算虚拟地址空间总大小。
- 物理内存的增量很少,是因为malloc分配的内存并不就马上分配实际存储空间,只有第一次使用,如第一次memset后才会分配。
- 由于每个物理内存页面大小是4k,不管memset其中的1k还是5k、7k,实际占用物理内存总是4k的倍数。所以物理内存的增量总是4k的倍数。
因此,不是malloc后就马上占用实际内存,而是第一次使用时发现虚存对应的物理页面未分配,产生缺页中断,才真正分配物理页面,同时更新进程页面的映射关系。这也是Linux虚拟内存管理的核心概念之一。
内存碎片
free释放内存时,有两种情况:
- chunk和top chunk相邻,则和top chunk合并
- chunk和top chunk不相邻,则直接插入到unsorted_list中
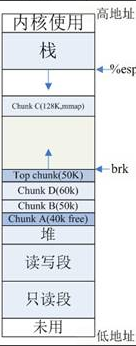
如上图示: top chunk是堆顶的chunk,堆顶指针brk位于top chunk的顶部。移动brk指针,即可扩充top chunk的大小。当top chunk大小超过128k(可配置)时,会触发malloc_trim操作,调用sbrk(-size)将内存归还操作系统。
以上图chunk分布图为例,按照glibc的内存分配策略,我们考虑下如下场景(假设brk其实地址是512k):
malloc 40k内存,即chunkA,brk = 512k + 40k = 552k malloc 50k内存,即chunkB,brk = 552k + 50k = 602k malloc 60k内存,即chunkC,brk = 602k + 60k = 662k free chunkA。
此时,由于brk = 662k,而释放的内存是位于[512k, 552k]之间,无法通过移动brk指针,将区域内内存交还操作系统,因此,在[512k, 552k]的区域内便形成了一个内存空洞即内存碎片。 按照glibc的策略,free后的chunkA区域由于不和top chunk相邻,因此,无法和top chunk 合并,应该挂在unsorted_list链表上。
缺点
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 多线程锁开销大, 需要避免多线程频繁分配释放。
- 内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。 比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
- 每个chunk至少8字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。