背景知识
- Language Representation Learning
下图展示了NLP的一般网络结构,下面一层是对词进行非上下文的编码,上面一层代表了在具体任务上对词进行基于上下文的编码。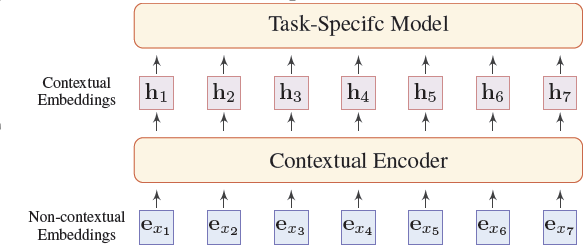
- Non-contextual Embeddings:
下面这层嵌入的目标是将离散的语言符号映射到连续的embedding空间中,一般在训练的过程中是随着具体任务的其他模型参数一起训练的。
这种嵌入有两个缺点,首先是这种嵌入是静态的,也就是说词嵌入表示不随着文本的改变而改变,第二点是会出现OOV问题,因此这种表示没办法对一词多义的词进行良好的表示,为了解决这个问题,character-level和sub-word level的word分解被广泛应用到NLP任务中,例如说CharCNN,FastTest,BPE等。 - Contextual Embeddings:
为了解决一词多义等词嵌入问题,必须结合上下文的信息来进行embedding,下面是几种方式,其中(a)和(b)属于sequence models,(c)属于None-sequence models。
(a)和(b)的优点是容易训练并且在不同的NLP任务中取得了不错的结果,缺点是无法捕捉长期依赖。(c)的优点是可以捕捉任意两个词之间的关系,更加灵活和强大,缺点是需要十分庞大的训练语料并且在小数据集上容易过拟合。
Overview of PTMs
- 预训练任务
预训练任务主要分成三种:
- Supervised learning
- Unsupervised learning(簇、密度、隐藏表示)
- Self-Supervised learning(MLM、NSP等)
Language Modeling (LM)
Probabilistic language modeling (LM)是最通用的无监督预训练任务,下面给出一个形式化的定义:
给定一个文本序列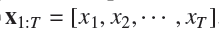
那么他的概率可以被分解成: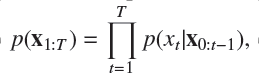
单向语言模型的缺点就是只能将其左方和他自己进行编码。Masked Language Modeling (MLM)
具体来说就是遮挡掉一部分token,然后试图使用其他的token预测遮盖掉的部分,这种预训练方法也有缺点,就是在训练阶段和fine-tune阶段的token出现数量不一致,因为在训练阶段遮挡了一部分tokenSequence-to-Sequence MLM (Seq2Seq MLM)
MLM通常被看做是一个分类任务,将一个masked的seq输入到encoder中,然后通过softmax输出分类概率,或者我们可以使用encoder-decoder架构,在encoder输入masked的seq,让decoder去生成对应的token(MASS、T5)Enhanced Masked Language Modeling (E-MLM)
对MLM任务进行提升,比如:- RoBERTa使用动态mask;
- UniLM将MLM任务扩展为单向、双向、seq2seq三种;
- XLM使用双向平行语料库进行训练,XLM的每个训练样本包含含义相同语言不同的两条句子,而不是像BERT中一条样本仅来自同1一语言,XLM模型中,我们可以对每组句子,用一个语言的上下文信息去预测另一个语言被遮住的token。因为句子对中不同的随机词语会被遮住,模型可以利用翻译信息去预测token。模型也接受语言ID和不同语言token的顺序信息,也就是位置编码。这些新的元数据能帮模型学习到不同语言的token间关系。
- structBERT:1/3的时候: 是上下句,分类为1,1/3的时候: 是上下句反序,分类为2,1/3的时候: 是不同文档的句子,分类为3 这个任务对句子对的任务效果好。
Permuted Language Modeling (PLM)
为了解决在训练阶段的[MASK]模型在微调阶段不存在的影响,Permuted Language Model被提出来了,其中个最有代表性的是Xlnet.Denoising Autoencoder (DAE)
输入一个带有噪声的seq,使用一个seq2seq模型去重建无噪声文本,有以下几种方法去破坏文本:- Token Masking:随机采样token然后将它们替换成[mask]
- Token Deletion:随机删除token,模型需要知道删除的token的位置
- Text Infilling:具有代表性的是spanBERT,随机屏蔽一段text,模型需要预测多少text被屏蔽。
- Sentence Permutation:随机打乱句子的顺序。
- Document Rotation:随机选择一个token然后旋转documet,以这个token为开始,模型需要确定document的真实开始位置。
Contrastive Learning (CTL)
对比学习假设一些文本对相对于随机选择来说有更高的语义相似性。对于一个文本对,定义一个得分方程s(x,y),任务的目标是最小化目标函数: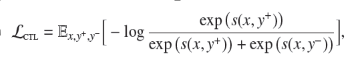
其中y+叫做和x相似的正样本,y-叫做和x不相似的负样本。得分方程通常通过learnable neural encoder学习,有两种方式,一种是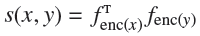
另一种是: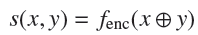
CTL的想法是”learning by comparison”,CTL通常比LM的复杂度低。
- Deep InfoMax (DIM)
最早是cv上面的概念,是通过最大化image representation 和local regions之间的互信息来提升image representation表达能力的。泛化到nlp里面就是把seq开头的字符(比如[cls])的hidden state作为文本的编码表示,DIM的目标是最大化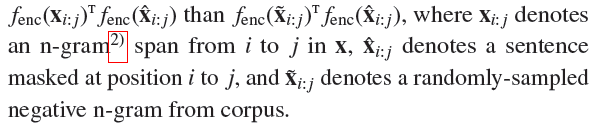
10. Replaced Token Detection (RTD)
主要思想和NCE一样,但是预测的是给定一个token的上下文预测这个token是否被替换。CBOW可以看做是一个RTD的简易版本。
ELECTRA:使用类似GAN的思想,具体参考论文。WKLM则是在entity-level替换单词(替换的单词和被替换的词具有相同的类别,也就是相似度比较高),然后训练模型判断实体是否被替换。
11. Next Sentence Prediction (NSP)
50%替换成随意的下一个句子,但是后来的工作对于这个预训练任务基本上没有采用,效果也很好。
12. Sentence Order Prediction (SOP)
打乱两个句子的顺序进行训练。
PTM的分类
- Representation Type:non-contextual and contextual models
- Architectures:LSTM, Transformer encoder, Transformer decoder, and the full Transformer architecture
- Pre-Training Task Types:2.1已经讨论过了
- Extensions:knowledge-enriched PTMs, multilingual or language-specific PTMs, multi-model PTMs, domainspecific PTMs and compressed PTMs.
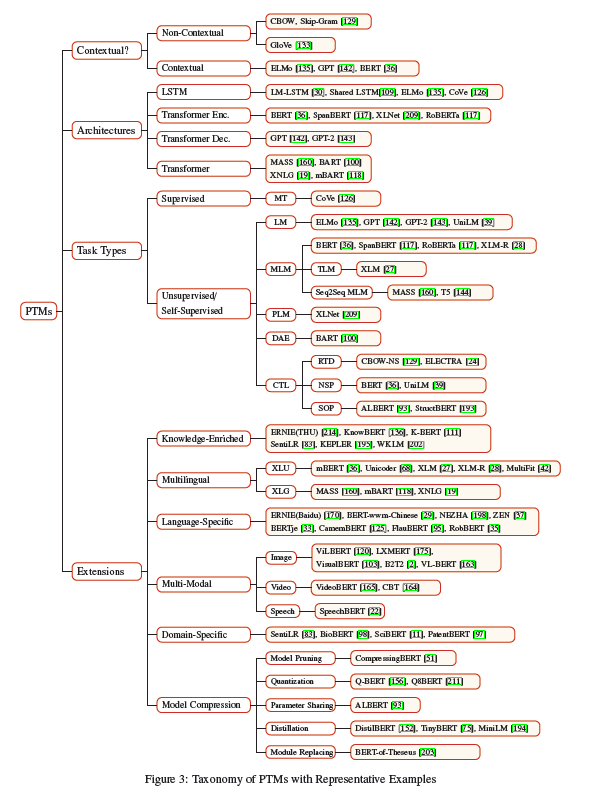
PTM扩展
PTM的扩展
- Knowledge-Enriched PTMs
- linguistically-informed BERT(LIBERT):在BERT中引入语言学知识;
- SentiLR:对每个单词引入情感标签;
- SenseBERT:在训练过程中除了经典BERT的MLM任务等等,还引入了WordNet里面的软标签,e.g. bass具有noun.food,noun.animal,noun.artifact,noun.person三种标签,模型需要预测这些意义;
- ERNIE:引入实体联系知识;
- KnowBERT:在输入文本中显式建模实体跨度(Entity spans),并使用实体链接器(Entity Linker)从KB中检测mention、检索相关的实体嵌入(Entity embeddings),以形成知识增强的实体跨度表示形式。然后使用word-to-entity attention将单词的表示重新上下文化,以携带全部的实体信息。
- KEPLER:将知识图谱的实体嵌入引入到预训练中;
- K-BERT:将知识图谱的三元组形式通过tree-form的形式输入到BERT;
- Pretrained encyclopedia:Weakly supervised
knowledge-pretrained language model:引入知识图谱的知识
这些模型大多数会在引入知识的时候更新参数,这会带来灾难遗忘的问题。
- K-Adapter:在训练不同的预训练任务的时候,使用不同的adapter,这样可以保证连续的知识融合。
- Enhancing pre-trained language representations with rich knowledge for machine reading comprehension:机器阅读理解模型,知识和文本融合,包括语言和事实知识的融合。
- Barack’s wife hillary: Using knowledge graphs for fact-aware language modeling:将语言模型扩展到知识图谱语言模型。
- Latent relation language models:将语言模型融合到latent relation language model
多语言
- Cross-Lingual Language Understanding (XLU)
- Multilingual BERT:使用共享词库和权重在wikipedia上训练top104个语言,每个训练样本是单语言的,虽然没有跨语言样本,但是展现出了较好的效果。
- XLM:前面提到过的,在平行语料中使用MLM训练。
- Cross-Lingual Language Generation (XLG)
- MASS:不用多说
- XNLG
- mBART
- Multi-Modal PTMs
- Video-Text PTMs
- VideoBERT
- CBT
- Uni-ViLM
- Image-Text PTMs
- ViLBERT
- LXMERT
- VisualBERT
- B2T2
- VLBERT
- Unicoder-VL
- UNITER
- Audio-Text PTMs
预训练模型压缩